




 Instagram
Instagram YouTube
YouTubeScientific Data Management Center Helping Scientists Focus on Science, Not Data
May 1, 2004
While terascale supercomputers are giving computational scientists unparalleled research capabilities, these systems are also producing huge amounts of data to be managed. Similar situations confront researchers using massive experimental facilities, where new experiments will be generating unprecedented quantities of scientific data. As a result, researchers often spend more time trying to find ways to manage their data instead of analyzing them.
To help scientists make effective and efficient use of these facilities and the resulting data, the Scientific Data Management Group in Berkeley Lab’s Computational Research Division is leading DOE’s project to coordinate the development and deployment of scientific data management software. Arie Shoshani, leader of the LBNL group, is also the lead principle investigator for the Scientific Data Management Center (SDM) funded under DOE’s SciDAC program. The center consists of four DOE laboratories (ANL. LBNL, LLNL, ORNL) and four universities (GTech, NCSU, NWU, SDSC). “Our purpose is not only to achieve efficient storage and access to the data, but also to enhance the effective use of the scientist's time by eliminating unproductive simulations, by providing specialized data-mining techniques, by streamlining time-consuming tasks, and by automating the scientist's workflows,” Shoshani wrote in a report on the project’s achievements to date. “Our approach is to provide an integrated scientific data management framework where components can be chosen by the scientists and applied to their specific domains. By overcoming the data management bottlenecks and unnecessary information-technology overhead through the use of this integrated framework, scientists are freed to concentrate on their science and achieve new scientific insights.”
Scientific research typically takes place in two phases: data collection/generation and data analysis. In the collection/generation phase, large datasets are generated by simulation programs or collected from experiments. This requires efficient parallel data systems that can keep up with the volumes of data generated. In the analysis phase, efficient indexes and effective analysis tools are necessary to find and focus on the information that can be extracted from the data, and the knowledge learned from that information.
Being able to analyze the data as they are generated is also important. For example, a scientist running a thousand-time-step 3D simulation can benefit from analyzing the data from individual steps in order to steer the simulation, saving unnecessary computation and accelerating scientific discovery. This requires sophisticated workflow tools, as well as efficient dataflow capabilities to move large volumes of data between the analysis components. For these reasons, the team uses an integrated framework that provides a scientific workflow capability, supports data mining and analysis tools, and accelerates storage access and data searching.
Progress at LBNL
Since the SDM Center was launched three years ago, the team has adopted, improved and applied various data management technologies to several scientific application areas, concentrating on typical scenarios provided by scientists from different disciplines. Not only did the team learn the important aspects of the data management problems from the scientist's point of view, but also provided solutions that led to actual results. In addition to overall direction and coordination of the center, the LBNL team has applied advanced indexing techniques and storage management to several application domains, described below.
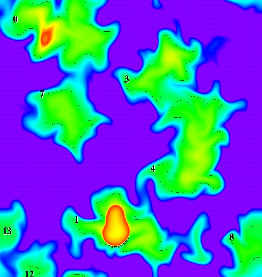
• A new specialized method for indexing high-dimensional data was applied to mesh data using bitmaps and achieved more than a tenfold speedup in generating regions and tracking them over time. The figure on the right shows the regions identified by their assigned numbers for a combustion application. The regions are tracked over time using the bitmaps to efficiently generate a movie of flame front progression. The key to this achievement is that this method works just as efficiently for selection conditions over multiple measures, a problem previously unsolved with any known indexing techniques. This bitmap- based indexing method was also applied to find collisions (events) of interest in high energy physics applications, and is currently used in the STAR experiment at BNL. This capability reduced the amount of data scientists have to sift through, reducing search times from weeks to hours.
• A new software module called Storage Resource Manager (SRM) has been used to provide wide-area access to the HPSS mass storage system. This enables scientific programs to remotely stream files from HPSS into the program’s disk space without explicitly requesting them, greatly simplifying the scientist’s task when using very large datasets. SRMs are also used in high energy physics and climate applications to move data robustly from data-generating sites to data-consuming sites. This task of moving terabytes reliably was prone to error and required constant monitoring and recovery from errors. The SRM technology now automates both the transfer and the recovery from transient errors, saving the scientist many hours of wasted time.
“The bottom line is that it is over 100 times faster than what I was doing before,” said Michael Wehner, a climate researcher at LBNL and SRM “power user.” “More importantly. I can see a path that will essentially reduce my own time spent on file transfers to zero in the development of the climate model database.”
For further information contact Arie Shoshani at shoshani@lbl.gov.
About Computing Sciences at Berkeley Lab
High performance computing plays a critical role in scientific discovery. Researchers increasingly rely on advances in computer science, mathematics, computational science, data science, and large-scale computing and networking to increase our understanding of ourselves, our planet, and our universe. Berkeley Lab’s Computing Sciences Area researches, develops, and deploys new foundations, tools, and technologies to meet these needs and to advance research across a broad range of scientific disciplines.