




 Instagram
Instagram YouTube
YouTubeCode Booster
Code optimization research explores multicore computing, wins award
April 1, 2008
A research paper exploring ways to make a popular scientific analysis code run smoothly on different types of multicore computers won a Best Paper Award at the IEEE International Parallel and Distributed Processing Symposium (IPDPS) this month.
The paper’s lead author and CRD researcher, Samuel Williams, and his collaborators chose the lattice Bolzmann code to explore a broader issue: how to make best use of multicore supercomputers. The multicore trend started recently, and the computing industry is expected to add more cores per chip to boost performance in the future. The paper described how the researchers developed a code generator that could efficiently and productively optimize a lattice Bolzmann code to deliver better performance on a new breed of supercomputers built with multicore processors.
The multicore trend is taking flight without an equally concerted effort by software developers. “The computing revolution towards massive on-chip parallelism is moving forward with relatively little concrete evidence on how to best use these technologies for real applications,” Williams wrote in the paper.
The researchers settled on the lattice Bolzmann code used to model turbulence in magnetohydrodynamics simulations that play a key role in areas of physics research, from star formation to magnetic fusion devices. The code, LBMHD, typi- cally performs poorly on traditional multicore machines.
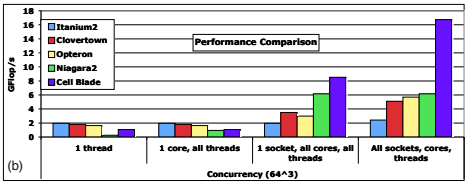
Comparison of (a) power efficiency and (b) runtime performance across all studied architectures for the 643 problem.
The optimization research resulted in a great improvement to the code performance — substantially higher than any published to date. The researchers also gained insight into building effective multicore applications, compilers and other tools.
The paper, “Lattice Boltzmann Simulation Optimization on Leading Multicore Platforms,” won the Best Paper Award in the application track. Jonathan Carter of NERSC, Lenny Oliker of CRD, John Shalf of NERSC and Kathy Yelick of NERSC co-authored the paper. The researchers presented their paper at the IPDPS in Miami. Yelick, who is NERSC Director, also was a keynote speaker at the symposium.
Oliker, Carter and Shalf also authored a paper that won the same award last year. The paper, “Scientific Application Performance on Candidate PetaScale Platforms,” was co-authored by CRD researchers Andrew Canning, Costin Iancu, Michael Lijewski, Shoaib Kamil, Hongzhang Shan and Erich Strohmaier. Stephane Ethier from the Princeton Plasma Physics Laboratory and Tom Goodale from Louisiana State University also contributed to the work.
In their more recent work on LBMHD, the researchers determined how well the code runs on processors used to buildcomputers today: Intel’s quad-core Clovertown, Advanced Micro Devices’ dual-core Opteron X2, Sun Microsystems’ eight-core Niagra2, and the eight-core STI Cell blade (designed by Sony, Toshiba and IBM). They also looked at Intel’s single- core Itanium2 to compare its more complex single core design with other simpler multicores.
The researchers first looked at why the original LBMHD performs poorly on these multicore systems. Williams and his fellow researchers found that, contrary to conventional wisdom, memory bus bandwidth didn’t present the biggest obstacle. Instead, lack of resources for mapping virtual memory pages, insufficient cache bandwidth, high memory latency, and/or poor functional unit scheduling did more to hamper the code’s performance, Williams said.
The researchers created a code generator abstraction for LBMHD in order to optimize it for different multicore architectures. The optimization efforts included loop restructuring, code reordering, software prefetching, and explicit SIMDization. The researchers characterized their effort as akin to the “auto-tuning methodology exemplified by libraries like ATLAS and OSKI.”
The results showed a wide range of performance results on different processors and pointed to bottlenecks in the hardware that prevented the code from running well. The optimization efforts also resulted in a huge gain in performance — the optimized code ran up to 14 times faster than the original version. It also achieved sustained performance for this code that is higher than any published to date: over 50 percent of peak flops on two of the processor architectures.
Compared with other processors, the Cell processor provided the highest raw performance and power efficiency for LBMHD. The processor’s design calls for a direct software control of the data movement between on-chip and main memory, resulting in the impressive performance. Overall, the researchers concluded, processor designs that focused on high throughput using sustainable memory bandwidth and a large number of simple cores perform better than processors with complex cores that emphasized sequential performance.
They also concluded that auto-tuning would be an important tool for ensuring that numerical simulation codes will perform well on future multicore computers.
Read about the researchers’ analyses of other processor architectures by checking out the paper on Williams’ website.
About Computing Sciences at Berkeley Lab
High performance computing plays a critical role in scientific discovery. Researchers increasingly rely on advances in computer science, mathematics, computational science, data science, and large-scale computing and networking to increase our understanding of ourselves, our planet, and our universe. Berkeley Lab’s Computing Sciences Area researches, develops, and deploys new foundations, tools, and technologies to meet these needs and to advance research across a broad range of scientific disciplines.