




 Instagram
Instagram YouTube
YouTubeClimateNet Aims to Improve Machine Learning Applications in Climate Science On a Global Scale
February 25, 2019
By Jon Bashor
Contact: cscomms@lbl.gov
Understanding climate change and its impact requires automatically detecting weather patterns and extreme events such as hurricanes and heat waves in large datasets and tracking them over time. For a variety of reasons, however, this is a challenging task and expert-designed heuristics to detect extreme events are plagued with large discrepancies and uncertainties even within the same dataset.
Additionally, many of the heuristics developed for this task are optimized for particular geographical regions and may not be applicable to other parts of the globe. Despite tremendous progress in our understanding of extreme weather and climate events, the task of automatic, efficient, and robust pattern detection has remained problematic.
Now a team at the Department of Energy's (DOE) Lawrence Berkeley National Laboratory (Berkeley Lab) is developing ClimateNet, a project that will bring the power of deep learning methods to identify important weather and climate patterns via expert-labeled, community-sourced open datasets and architectures. Once the project gathers momentum, the resulting deep learning models would be able to identify complex weather and climate patterns on a global scale, according to Karthik Kashinath, who is leading the project. Kashinath is a member of the Data & Analytics Services Group at the National Energy Research Scientific Computing Center (NERSC), a DOE Office of Science User Facility at Berkeley Lab.
Accelerating the Pace of Climate Research
Most recently, both Kashinath and Prabhat, leader of NERSC’s Data & Analytics Services Group, presented their work at the 2018 meeting of the American Geophysical Union (AGU) held Dec. 10-14 in Washington, D.C. Prabhat gave an invited talk on "Towards Exascale Deep Learning for Climate Science" and Kashinath gave a talk on “Deep Learning recognizes weather and climate patterns” and presented a poster on ClimateNet, both of which several other Berkeley Lab and UC Berkeley researchers contributed to. This research is supported in part by the Big Data Center collaboration between NERSC, Intel and five Intel Parallel Computing Centers that was launched in 2017 to enable capability data-intensive applications on NERSC’s supercomputing platforms.
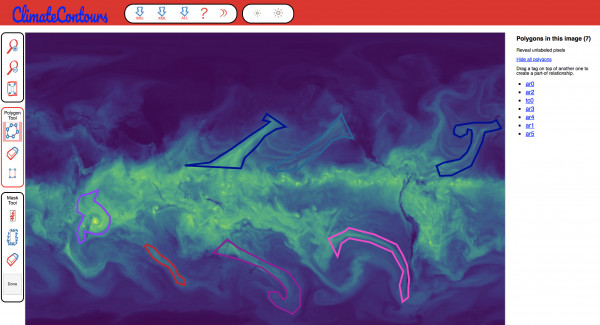
To apply quality control to the images for ClimateNet, Berkeley Lab researchers have modified the "Label-Me" tool developed at MIT and created a web interface called ClimateContours.
Discussions about the role of machine learning in pattern recognition were common at the AGU meeting on climate, geophysics, geochemistry and others, as well as a workshop on how machine learning can be used in climate modeling, Kashinath noted.
"Machine learning and deep learning are really bringing sweeping changes to the field," he said. "There were six sessions on machine learning in the geosciences."
Both scientists were often approached by colleagues, teachers and students throughout the conference, asking questions about when ClimateNet will be ready, will it work on observational data (it will) and whether it would be useful in classrooms (yes).
According to Prabhat and Kashinath, ClimateNet could dramatically accelerate the pace of climate research that requires recognizing complex patterns in large datasets. Currently, it can take a scientist years to research a problem, develop a hypothesis to test an idea and then produce results that will stand up to peer review. With the kind of deep learning analysis that will be developed under ClimateNet, the two say that the lifecycle of such problems could be greatly reduced.
Creating ClimateNet
As the term implies, machine learning requires learning. Teaching a computer to learn means that data needs to be curated and labeled, models need to be developed and then analyzed repeatedly. For ClimateNet, this means creating a database of carefully curated images in which climate experts label the images to tell the computer what it's looking at. The concept is analogous to the process behind tagging photos of friends in Facebook – after explicitly marking photos as belonging to the same person a number of times, Facebook “learns” to apply the tag to new photo posts of the same person.
In the past, climate researchers would label such images often using their own heuristics, which could lead to discrepancies in results, even between researchers using the same database. In order to apply quality control to the images for ClimateNet, Kashinath, Mayur Mudigonda, Adrian Albert, Kevin Yang and Jiayi Chen have modified the "Label-Me" tool developed at MIT and created a web interface called ClimateContours, which was unveiled at the AGU meeting, to crowdsource the "hand" labeling task. Examples, which will be modified and fine-tuned by users, have been created using the Toolkit for Extreme Climate Analysis (TECA) software, which implements expert-specified heuristics to generate label information.
The first phase of the project will be to create a database of 10,000 to 100,000 labeled images, which will then be used to train powerful machine learning models to more quickly and accurately to identify about 10 classes of distinct weather and climate patterns for understanding extreme events. Deep learning, a flavor of machine learning, takes raw data and extracts useful information for pattern detection at multiple levels of abstraction. The power of deep learning is truly realizable only when both large amounts of data and high-quality labels are available to train these models on large machines, such as the Cori supercomputer at NERSC. The former already exists in climate science, and the latter is the central goal of the ClimateNet project.
Because ClimateContours is publicly available, Prabhat and Kashinath expect climate experts from around the world to contribute datasets and label them. To jump-start the project, they are planning to conduct targeted hackathons at several labs, universities and conferences, inviting researchers to spend an hour or so and label some data.
"We think we will have a good database to work with in a few months," Prabhat said.
The database will continually grow and evolve as more people contribute. For quality control, sets of expert-labeled images will be inserted to test how well the users are performing in the labeling task and to guide them in labeling more precisely and accurately. And to augment existing datasets from model output, images from satellite observations and reanalyses products will be introduced. There is plenty of material to work with, as an estimated five petabytes of climate data has been produced and archived worldwide. And as more labels are added, the ClimateNet database will keep getting bigger and the resulting deep learning models better.
Analyze Globally, Benefit Locally
“With a trained deep learning architecture, global climate data can be analyzed rapidly and efficiently to determine the changing behavior of extreme weather such as the frequency and ferocity of tropical storms, the intensity and geometry of atmospheric rivers and their relationship with El Nino,” Prabhat said. “Better analysis tools will improve localized understanding of how such storms form, when they will make landfall and how intense they will be. We will be able to extract impact-related metrics that people really care about at the end of the day."
The end result of the project will be to overcome the limitations of the heuristic methods that have been developed over several decades and bring high-speed, high-fidelity precision analytics to climate science, said Prabhat, who has been applying machine learning to climate data for the past three years and given Berkeley Lab a head start in the field.
"We're positioned in the right place, surrounded by climate experts like Bill Collins and Michael Wehner, and our computer science colleagues at UC Berkeley who have been pioneering the development of advanced machine learning algorithms for over 20 years," Prabhat said. "We have large datasets and the computational horsepower to analyze them. ClimateNet will create the high-quality labeled database that the community needs."
About Computing Sciences at Berkeley Lab
High performance computing plays a critical role in scientific discovery. Researchers increasingly rely on advances in computer science, mathematics, computational science, data science, and large-scale computing and networking to increase our understanding of ourselves, our planet, and our universe. Berkeley Lab’s Computing Sciences Area researches, develops, and deploys new foundations, tools, and technologies to meet these needs and to advance research across a broad range of scientific disciplines.