




 Instagram
Instagram YouTube
YouTubeCeleste Enhancements Create New Opportunities in Sky Surveys
New parallel implementation of statistical analysis model dramatically increases data analysis speed
November 11, 2016
By Kathy Kincade
Contact: cscomms@lbl.gov

The Sloan Digital Sky Survey has created the most detailed three-dimensional maps of the Universe ever made, with deep multi-color images of one third of the sky, and spectra for more than three million astronomical objects.
Berkeley, CA – Celeste, a statistical analysis model designed to enhance one of modern astronomy’s most time-tested tools—sky surveys—has gotten a major upgrade that dramatically scales up the process of cataloging astronomical objects.
The Celeste code, developed under Berkeley Lab’s MANTISSA project, implements statistical inference to build a fully generative model to mathematically locate and characterize light sources in the sky. When it was first released in 2015, Celeste was limited to single-node execution on at most hundreds of megabytes of astronomical images. In the case of the Sloan Digital Sky Survey, which is the dataset used for this research, this analysis is conducted by identifying points of light in nearly 5 million images of approximately12 megabytes each – a dataset of 55 terabytes.
“Celeste is a much better model for identifying the astrophysical sources in the sky and the calibration parameters of each telescope,” said David Schlegel, an astrophysicist at Lawrence Berkeley National Laboratory and principal investigator on the Baryon Oscillation Spectroscopic Survey (BOSS, part of SDSS) and co-PI on the DECam Legacy Survey (DECaLS). “It allows us to mathematically define what we are solving, which is very different from the traditional approach to mapping and cataloging regions of the sky."
Now, Celeste is even better. Researchers from UC Berkeley, Intel, the National Energy Research Scientific Computing Center (NERSC), Lawrence Berkeley National Laboratory, Julia Computing and JuliaLabs@MIT have unveiled a parallel version of the Celeste code, an innovation that leverages 8,192 Intel® Xeon® processors in Berkeley Lab’s new Cori supercomputer and Julia, the high-performance, open-source scientific computing language.
“Astronomical surveys are the primary source of data about the Universe beyond our solar system,” said Jeff Regier, a postdoctoral fellow in the UC Berkeley Department of Electrical Engineering and Computer Sciences who has been instrumental in the development of Celeste. “Through Bayesian statistics, Celeste combines what we already know about stars and galaxies from previous surveys and from physics theories, with what can be learned from new data. Its output is a highly accurate catalog of galaxies’ locations, shapes and colors. Such catalogs let astronomers test hypotheses about the origin of the Universe, as well as about the nature of dark matter and dark energy.”
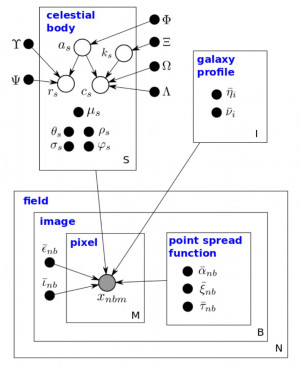
The Celeste graphical model. Shaded vertices represent observed random variables. Empty vertices represent latent ran- dom variables. Black dots represent constants. Constants denoted by uppercase Greek characters are fixed and denote parameters of prior distributions. The remaining constants and all latent random variables are inferred.
Using the new parallel implementation, the Celeste team dramatically increased the speed of this analysis by an estimated 225x. This enabled the processing of more than 20 thousand images, or 250 gigabytes – an increase of more than 3 orders of magnitude compared with previous iterations. “It is exactly to enable such cutting-edge machine-learning algorithms on massive data that we designed the Julia language,” said Viral Shah, CEO of Julia Computing. “Researchers can now focus on problem solving rather than programming.”
NERSC provided the extensive computing resources the team needed to apply such a complex algorithm to so much data, assisting with many aspects of designing a program to run at scale, including load balancing and interprocess communication, Regier noted.
“Practically all the significant code that runs on supercomputers is written in C/C++ and Fortran, for good reason: efficiency is critically important,” said Pradeep Dubey, Intel Fellow and Director of the Parallel Computing Lab at Intel. “With Celeste, we are closer to bringing Julia into the conversation because we’ve demonstrated excellent efficiency using hybrid parallelism—not just processes, but threads as well—something that’s still impossible to do with Python or R.”
Alan Edelman, co-creator of the Julia language and professor of applied mathematics at MIT, said, “The JuliaLabs group at MIT is thrilled and impressed with this advancement in the use of Julia for High Performance Computing. The dream of ‘ease of use’ and (‘and’ not ‘or!’) ‘high performance’ is becoming a reality.”
The Celeste project is at the cutting edge of scientific big data analysis along multiple fronts, added Prabhat, NERSC Data and Analytics Services Group Lead and PI for the MANTISSA project. “From a scientific perspective, it is one of the first codes that can conduct inference across multiple imaging surveys and create a unified catalog with uncertainties,” he said. “From a methods perspective, it is the first demonstration of large scale variational inference applied to 100s of GBs of scientific data. From a software perspective, I believe it is one of the largest applications of the Julia language to a significant problem: we have integrated the DTree scheduler and utilized MPI-3 one-sided communication primitives.”
This implementation of Celeste also demonstrated good weak and strong scaling properties on 256 nodes of the Cori Phase I system, Prabhat added. The group’s next step will be to apply Celeste to the entire SDSS imaging dataset, followed by a joint SDSS+DeCALS analysis on Cori Phase II.
###
About the National Energy Research Scientific Computing Center (NERSC) and Lawrence Berkeley National Laboratory: The National Energy Research Scientific Computing Center (NERSC) is the primary high-performance computing facility for scientific research sponsored by the U.S. Department of Energy's Office of Science. Located at Lawrence Berkeley National Laboratory, the NERSC Center serves more than 6,000 scientists at national laboratories and universities researching a wide range of problems in combustion, climate modeling, fusion energy, materials science, physics, chemistry, computational biology, and other disciplines. Berkeley Lab is a U.S. Department of Energy national laboratory located in Berkeley, California. It conducts unclassified scientific research and is managed by the University of California for the U.S. DOE Office of Science.
About Julia, Julia Computing and JuliaLabs@MIT: Julia is the high performance open source computing language that is taking astronomy, finance and other big data analytics fields by storm. Julia is being used by researchers, data scientists, quants and algorithmic traders at Intel, DARPA, BlackRock, US Federal Reserve, FAA, Bank of England, UC Berkeley, Stanford, MIT, Harvard, NYU and others. Julia Computing is the for-profit Julia consulting firm founded by the co-creators of the Julia computing language to help researchers and businesses maximize productivity and efficiency using Julia. JuliaLabs@MIT, led by Professor Alan Edelman, conducts research using the Julia language.
Intel is a registered trademark of Intel Corporation in the United States and other countries.
About Computing Sciences at Berkeley Lab
High performance computing plays a critical role in scientific discovery. Researchers increasingly rely on advances in computer science, mathematics, computational science, data science, and large-scale computing and networking to increase our understanding of ourselves, our planet, and our universe. Berkeley Lab’s Computing Sciences Area researches, develops, and deploys new foundations, tools, and technologies to meet these needs and to advance research across a broad range of scientific disciplines.