
Breakthrough
Lehigh University and Lawrence Berkeley National Laboratory (Berkeley Lab) researchers have developed an accelerating sparse accumulation (ASA) architecture, specialized hardware that enables faster computation on data sets that have a high number of zero values. Their work was first published in ACM Transactions on Architecture and Code Optimization and has led to a provisional patent.
Background
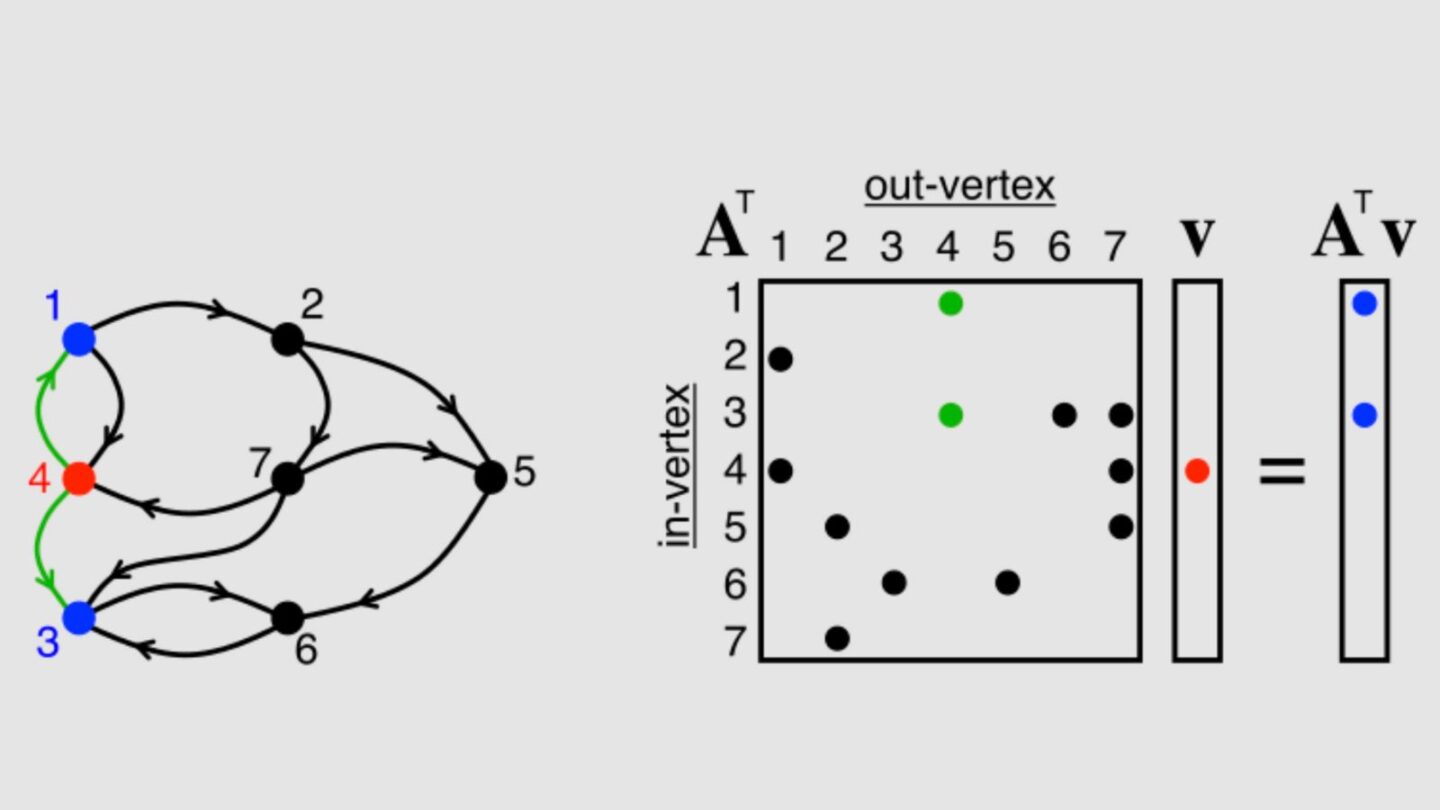
Large data sets in prominent scientific applications often demonstrate sparsity characteristics (data with zero values). Researchers in bioinformatics and physical sciences run into problems when they try to create graphs using data sets that are partially empty (represented by a sparse matrix). The ASA architecture accelerates sparse computation, allowing researchers to perform their bioinformatics and physical studies in shorter chunks of time. The ASA architecture allows researchers to more easily scale their data and decrease the runtime of their operations. This hardware is extremely portable and can be integrated easily into general-purpose multi-core computers. Finally, ASA is easily controlled with a simple software interface.
The ASA architecture could accelerate a wide variety of very useful and important algorithms. For instance, microbiome researchers could use ASA to run metagenomic assembly and similarity clustering algorithms such as Markov Cluster Algorithms that quickly characterize the genetic markers of all of the organisms in a soil sample.
Breakdown
The ASA architecture includes a hardware buffer, a hardware cache, and a hardware adder. It takes two sparse matrices, performs a matrix multiplication, and outputs a sparse matrix. The ASA only uses non-zero data when it performs this operation, which makes the architecture more efficient. The hardware buffer and the cache allow the computer processor to easily manage the flow of data; the hardware adder allows the processor to quickly generate values to fill up the empty matrices.
Once these values are calculated, the ASA system produces an output. This operation is a building block that the researcher can then use in other functions. For instance, researchers could use these outputs to generate graphs or they could process these outputs through other algorithms such as a Sparse General Matrix-Matrix Multiplication (SpGEMM) algorithm.
Co-authors
Chao Zhang, Maximilian Bremer, Cy Chan, John M Shalf, and Xiaochen Guo.
Publication
Chao Zhang, Maximilian Bremer, Cy Chan, John M Shalf, and Xiaochen Guo
ACM Transactions on Architecture and Code Optimization (TACO) Volume 19, Issue 4, Article No.: 49, Pages 1 – 24
DOI: https://doi.org/10.1103/PhysRevLett.132.251904
Funding
Project 38, Visiting Faculty Program, Sustainable Research Pathways
About Computing Sciences at Berkeley Lab
High performance computing plays a critical role in scientific discovery. Researchers increasingly rely on advances in computer science, mathematics, computational science, data science, and large-scale computing and networking to increase our understanding of ourselves, our planet, and our universe. Berkeley Lab’s Computing Sciences Area researches, develops, and deploys new foundations, tools, and technologies to meet these needs and to advance research across a broad range of scientific disciplines.
About Computing Sciences at Berkeley Lab
High performance computing plays a critical role in scientific discovery. Researchers increasingly rely on advances in computer science, mathematics, computational science, data science, and large-scale computing and networking to increase our understanding of ourselves, our planet, and our universe. Berkeley Lab's Computing Sciences Area researches, develops, and deploys new foundations, tools, and technologies to meet these needs and to advance research across a broad range of scientific disciplines.