




 Instagram
Instagram YouTube
YouTubeBerkeley Lab Climate Software Honored for Pattern Recognition Advances
September 21, 2015
By Kathy Kincade
Contact: cscomms@lbl.gov
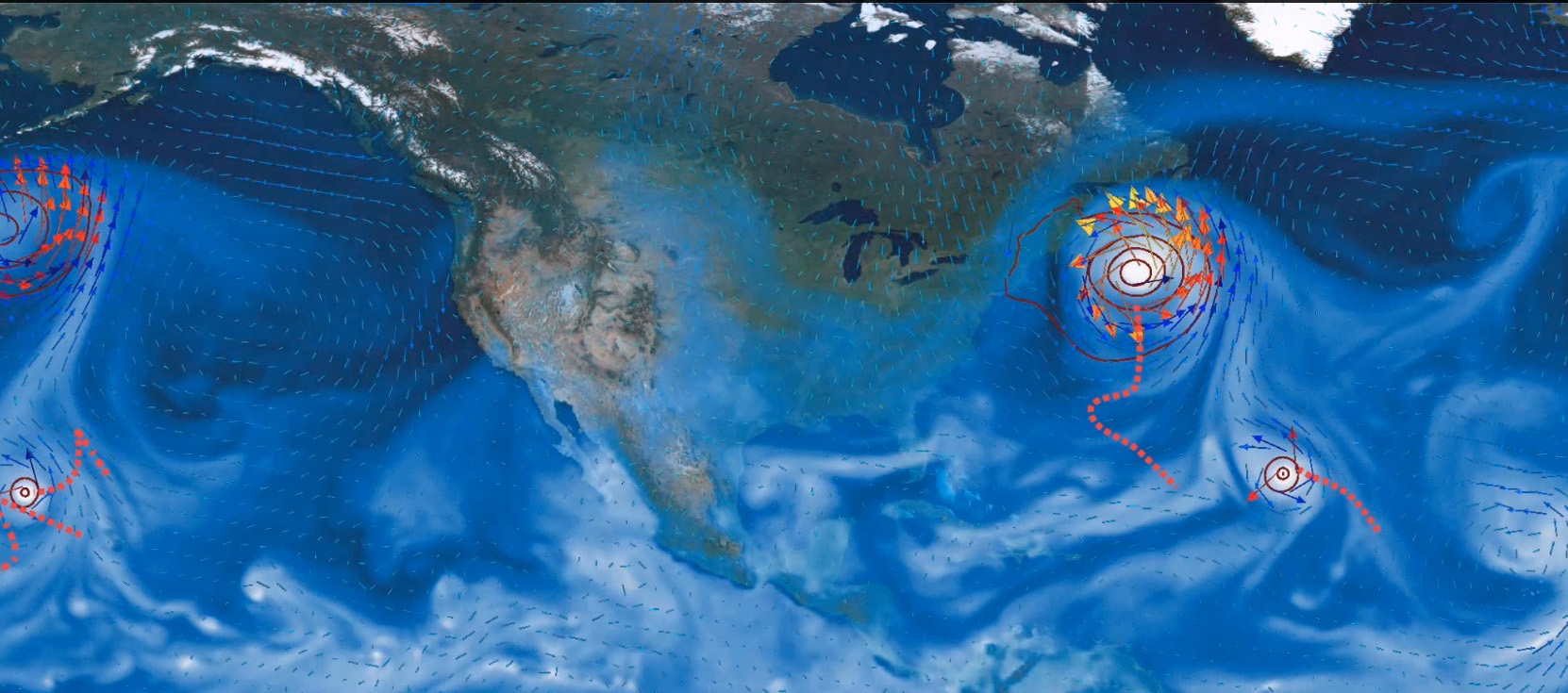
TECA implements multi-variate threshold conditions to detect and track extreme weather events in large climate datasets. This visualization deptics tropical cyclone tracks overlaid on atmospheric flow patterns.
The Toolkit for Extreme Climate Analysis (TECA) developed at Lawrence Berkeley National Laboratory to help climate researchers detect extreme weather events in large datasets, has been recognized for its achievements in solving large-scale pattern recognition problems.
“TECA: Petascale Pattern Recognition for Climate Science,” a paper presented by scientists from Berkeley Lab and Argonne National Laboratory at the 16th International Conference on Computer Analysis of Images and Patterns (CAIP), was awarded CAIP’s Juelich Supercomputing Center prize for the best application of HPC technology in solving a pattern recognition problem.
The paper, authored by Prabhat, Surendra Byna, Eli Dart, Michael Wehner and Bill Collins of Berkeley Lab and Venkat Vishwanath of Argonne, is funded in part by Berkeley Lab’s Scientific Focus Area entitled “Calibrated and Systematic Characterization, Attribution, and Detection of Extremes (CASCADE),” in which pattern recognition is being analyzed to better identify extreme weather events associated with climate change. The researchers demonstrated how TECA, running at full scale on NERSC’s Hopper system (a Cray XE6) and Argonne’s Mira system (an IBM BG/Q), reduced the runtime for pattern detection tasks from years to hours.
Modern climate simulations produce massive amounts of data, requiring sophisticated pattern recognition on terabyte- to petabyte-sized datasets. For this project, Prabhat and his colleagues downloaded 56 TB of climate data from the fifth phase of the Coupled Model Intercomparison Project (CMIP5) to NERSC. Their goal was to access subsets of those datasets to identify three different classes of storms: tropical cyclones, atmospheric rivers and extra-tropical cyclones.
All of the datasets were accessed through a portal created by the Earth Systems Grid Federation to facilitate the sharing of data—in this case, atmospheric model data at six-hour increments running out to the year 2100 that was stored at 21 sites around the world, including Norway, the United Kingdom, France, Japan and the United States. NERSC’s Hopper system was used to preprocess the data, which took about two weeks and resulted in a final 15 TB dataset.
ESnet's High-Speed Network Critical
Moving the data from NERSC to the Argonne Leadership Computing Facility (ALCF) was accomplished using ESnet’s 100-gigabit-per-second network backbone. Globus, a software package developed for moving massive datasets easily, further sped things up. Several datasets were moved during the project, with much better performance than the original data staging; for example, a replication of the entire raw project dataset (56 TB) from NERSC to ALCF took only two days.
“ESnet exists to enable precisely this sort of work,” said Dart, a network engineer at ESnet who oversaw the data transfer. “It is essentially impossible, in the general case, to assemble large-scale datasets from this big, distributed archive without a high-performance, feature-rich network to connect all the different pieces. Participating in projects like this not only helps the project but helps ESnet understand what the needs of the scientists are so that we can run our networks better and help other groups that might have similar problems.”
Once the data was received at ALCF, Vishwanath helped optimize the code to scale to Mira’s massively parallel architecture and high-performance storage system, thereby enabling TECA to fully exploit the system. The job ran simultaneously on 755,200 of Mira’s 786,432 processor cores, using 1 million processor hours in just an hour and a half.
“We have now developed capabilities to scale TECA to entire supercomputers—Hopper and Edison at NERSC and Mira at ALCF—and ask sophisticated questions about how extreme weather is expected to change in future climate regimes,” said Prabhat, who leads NERSC’s Data and Analytics Services team. “Only by running at these large scales are we able to process these terabyte datasets in under an hour. Attempting similar analytics on a single machine would be simply intractable. TECA is enabling climate scientists to extract value from large-scale simulation and observational datasets.”
Related reading:
About Computing Sciences at Berkeley Lab
High performance computing plays a critical role in scientific discovery. Researchers increasingly rely on advances in computer science, mathematics, computational science, data science, and large-scale computing and networking to increase our understanding of ourselves, our planet, and our universe. Berkeley Lab’s Computing Sciences Area researches, develops, and deploys new foundations, tools, and technologies to meet these needs and to advance research across a broad range of scientific disciplines.