




 Instagram
Instagram YouTube
YouTubeBerkeley Lab-Developed Digital Library is a Game Changer for Environmental Research
ESS-DIVE is a new digital library for the Department of Energy's environmental science data
July 24, 2018
By Linda Vu
Contact: cscomms@lbl.gov

Data collection in Rifle, Colorado, for EESA’s Sustainable Systems Scientific Focus Area 2.0 research project. (Photo credit: Berkeley Lab)
Environmental data are crucial for planning our water and energy future, safeguarding against environmental threats and building resilient infrastructure. By using high-quality observations collected over years to power computer models, researchers can examine and predict ecosystem and watershed behaviors over the course of seasons to decades to centuries. However, storing, accessing and incorporating environmental data into models is challenging due to the diversity of the datasets, which include measurement of properties associated with bedrock, groundwater, soils, vegetation and atmospheric compartments of environmental systems.
Now accessing archival data generated by environmental field, experimental and modeling activities has gotten much easier with the April 1 launch of ESS-DIVE (Environmental System Science – Data Infrastructure for a Virtual Ecosystem)—a digital archive that serves as a repository for hundreds of U.S. Department of Energy (DOE)-funded research projects under the agency’s Environmental System Science umbrella, which includes the Subsurface Biogeochemical Research and Terrestrial Ecosystem Sciences programs. The digital library also serves datasets that were previously stored in DOE’s Carbon Dioxide Information Analysis Center archive.
The digital library was built by a collaboration of scientists in Lawrence Berkeley National Laboratory’s (Berkeley Lab’s) Computational Research Division (CRD) and Earth & Environmental Sciences Area (EESA), the National Energy Research Scientific Computing (NERSC) and digital librarians at the National Center for Ecological Analysis and Synthesis (NCEAS)—a research center based at UC Santa Barbara.
“By moving to a digital library, we are going from a one-time use to a reusable data paradigm. Because ESS-DIVE stores ‘data packages,’ which are essentially collections of related data files and metadata, we no longer just have a research paper to reference but also the underlying data that led to those results. This means that other scientists can review the analyses, validate results, study different scenarios and reuse the data for other purposes,” says Deb Agarwal, a scientist in Berkeley Lab’s CRD and lead of the ESS-DIVE project.
And when ESS-DIVE becomes a DataONE member node in the near future, she notes that it will become an even more powerful tool, as the library’s DOE-funded data contents will be discoverable in cross-catalogue searches. DataONE supports enhanced search and discovery of earth and environmental data across a number of repositories managed by its members.
“This digital library is a total game-changer for scientists like me. ESS-DIVE will make it much easier for scientists to archive our data using standardized formats, to make data publicly available and to find and integrate data from various research studies. Although some projects had independent systems to manage their data, those efforts were not coordinated, and there was no central location where data across the DOE’s environmental research program were available,” says Charuleka Varadharajan, a research scientist in Berkeley Lab’s EESA and deputy lead for the ESS-DIVE project.
“A lot of our datasets require really intensive fieldwork to collect. No field season is ever going to be the same because the environmental conditions are always changing. And to accurately predict long-term ecosystem behavior, we need to feed and validate our models with years to decades of diverse observations. This means that every single data point is incredibly valuable and has the potential to be reused for purposes that go way beyond the intent for which it was originally collected,” Varadharajan adds. “That’s why this work is so important.”
It Takes a Community to Build an Effective Archive
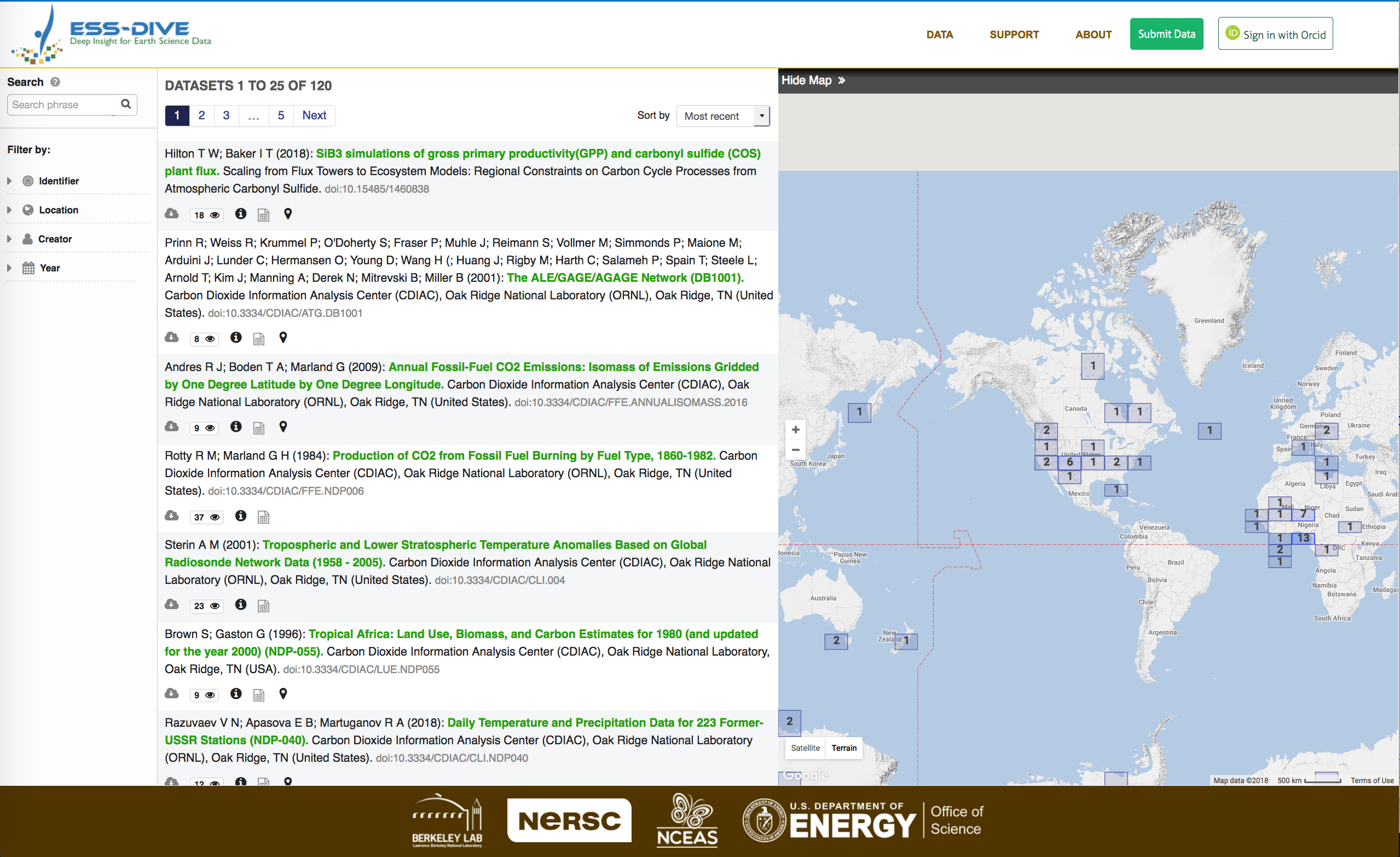
The ESS-DIVE Data Access Portal enables search of the entire text within the metadata submitted by contributors, and allows filtering by geographic location through a map, and other criteria such as DOI, authors, keywords and publication year.
Interdisciplinary research is a hallmark of Berkeley Lab, and over the years Lab computer and environmental scientists have collaborated to help a number of large ESS projects—like the Berkeley Water Center, AmeriFlux, Watershed Function SFA, and Next Generation Ecosystem Experiment (NGEE)-Tropics—curate, manage, store and publicly share their data. From these collaborations, Agarwal learned early on that the most effective way to build useful scientific tools and accelerate adoption of any kind of data standard or technology is to work in partnership with the scientific community.
“We have to embed ourselves with the project’s scientists. We have to sit down and work with them to understand their challenges and define an infrastructure that fits with their process of curating and publishing data, such that it is a natural part of their workflow,” says Agarwal. “Our end goal is to make these data publicly available and easily accessible. If researchers only upload their data once their paper is published and the research is complete, then our archive becomes an afterthought and a burden.”
In the case of ESS-DIVE, Agarwal and her team included functionalities that allow researchers to upload their data and keep it proprietary as they work on the paper. Once the paper is published, researchers can go into the library and easily make their data public.
ESS-DIVE also includes tools that allow users to access data, contribute and publish data and track data downloads. And because each data package is assigned a unique Digital Object Identifier (DOI) when it’s uploaded, researchers can now cite the dataset that they used. The DOIs are assigned with the help of the Office of Scientific and Technical Information, which also helped with the transition of pre-existing data into ESS-DIVE.
“The DOI is extremely useful for data generators, who typically work hard to collect their data and clean and process it. With this identifier, the data set itself becomes a product that can be cited,” says Varadharajan. “That way, if the data were used in a publication that the data generators are not co-authors on, they would still be able to get credit for producing the data.”
The current implementation of ESS-DIVE’s web portal is built on top of the Metacat repository software developed by NCEAS. Metacat stores metadata using the Ecological Metadata Standard, provides an application programming interface to facilitate the input and retrieval of data packages and includes an engine to query across a number of metadata attributes.
All basic components of the architecture run inside Docker containers, which allow multiple redundant instances of ESS-DIVE to be available in case of outages at a site. The primary ESS-DIVE instance runs on NERSC’s Spin, a Docker-based edge-services technology that can access the facility’s supercomputers and storage systems on the back end. In addition, copies of the library’s data and metadata are stored on a server in Berkeley Lab’s Information Technology Division and will soon be replicated via Metacat to NCEAS and the DataONE federation, which guarantees broad redundant availability.
“Spin is great because it effectively allows us to run a next-generation science gateway at NERSC,” says Agarwal. “We can install all of the different nuanced interaction capabilities in an easily deployable space, which is then held in a Docker container. This means that users can upload and interact with data in a controlled environment, but the infrastructure can access all of the local libraries that we’ve stored out in NERSC’s project space. And because everything is contained within a Docker container, we can also create backup instances relatively easily.”
In addition to Agarwal and Varadharajan, other key Berkeley Lab contributors to ESS-DIVE include Shreyas Cholia (CRD), Cory Snavely (NERSC), Valerie Hendrix (CRD), Fianna O’Brien (CRD), Abdelrahman Elbashandy (CRD), Karen Whitenack (CRD), Yeongshnn Ong (CRD) and William Riley (EESA). NERSC is a DOE Office of Science user facility.
More information about ESS-DIVE:
https://eesa.lbl.gov/data-archive-amplify-impact-ecosystem-research/
About Computing Sciences at Berkeley Lab
High performance computing plays a critical role in scientific discovery. Researchers increasingly rely on advances in computer science, mathematics, computational science, data science, and large-scale computing and networking to increase our understanding of ourselves, our planet, and our universe. Berkeley Lab’s Computing Sciences Area researches, develops, and deploys new foundations, tools, and technologies to meet these needs and to advance research across a broad range of scientific disciplines.