




 Instagram
Instagram YouTube
YouTubeEtalumis ‘Reverses’ Simulations to Reveal New Science
New Probabilistic Programming Framework a Finalist for Best Paper at SC19
November 12, 2019
By Keri Troutman
Contact: cscomms@lbl.gov
Scientists have built simulations to help explain behavior in the real world, including modeling for disease transmission and prevention, autonomous vehicles, climate science, and in the search for the fundamental secrets of the universe. But how to interpret vast volumes of experimental data in terms of these detailed simulations remains a key challenge. Probabilistic programming offers a solution—essentially reverse-engineering the simulation—but this technique has long been limited due to the need to rewrite the simulation in custom computer languages, plus the intense computing power required.
To address this challenge, a multinational collaboration of researchers using computing resources at Lawrence Berkeley National Laboratory’s National Energy Research Scientific Computing Center (NERSC) has developed the first probabilistic programming framework capable of controlling existing simulators and running at large-scale on HPC platforms. The system, called Etalumis (“simulate” spelled backwards), was developed by a group of scientists from the University of Oxford, University of British Columbia (UBC), Intel, New York University, CERN, and NERSC as part of a Big Data Center project.
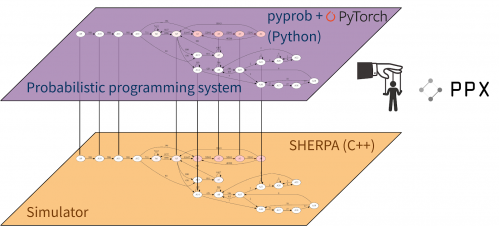
An overview of the Etalum pyprob software framework that controls the existing HPC simulation.
Etalumis performs Bayesian inference—a method of statistical inference in which Bayes' theorem is used to update the probability for a hypothesis as more evidence or information becomes available—essentially inverting the simulator to predict input parameters from observations. The team deployed Etalumis for the first time for the Large Hadron Collider (LHC) at CERN, bringing a new level of interpretability to data analysis from the LHC’s high-energy physics detectors. A paper based on Etalumis has been selected as a finalist for Best Paper at SC19. The authors will speak about Etalumis at SC19 on Tuesday, November 19 at 4:30 p.m.
From Days to Minutes
Bayesian inference is used in virtually all scientific disciplines, according to Frank Wood, an Etalumis collaborator, Associate Professor of Computer Science at UBC, and one of the pioneers of probabilistic programming.
“I was particularly interested in applying Bayesian inference to an extremely complex physics problem, and high-energy physics detectors felt like the perfect proving ground for our group’s seminal research,” he says. “The Etalumis project provided a unique opportunity to combine a cutting-edge neural network based on an ‘inference compilation’ approach with a software framework (pyprob) to directly couple this inference engine to existing detailed particle physics simulators and run it on HPC-scale resources.”
Scientists already have robust simulation software packages that model the physics and everything that occurs within the detector. Etalumis brings in probabilistic programming to couple with this existing software, essentially giving researchers the ability to say “We had this observation; how did we get there?”
“This project is exciting because it makes existing simulators across many fields of science and engineering subject to probabilistic machine learning,” says Atilim Gunes Baydin, lead developer of the Etalumis project and lead author of the SC19 paper. Gunes is currently a postdoctoral researcher in machine learning at the University of Oxford. “This means the simulator is no longer used as a black box to generate synthetic training data, but as an interpretable probabilistic generative model that the simulator’s code already specifies, in which we can perform inference.
“We need to be able to control the program to run down every possibility, so in this project we added this capability as a software layer,” adds Wahid Bhimji, a Big Data Architect in the Data and Analytics Services team at NERSC. However, performing inference in such complex settings brings computational challenges. “Conventional methods for this kind of Bayesian inference are extremely computationally expensive,” Bhimji adds. “Etalumis allows us to do in minutes what would normally take days, using NERSC HPC resources.”
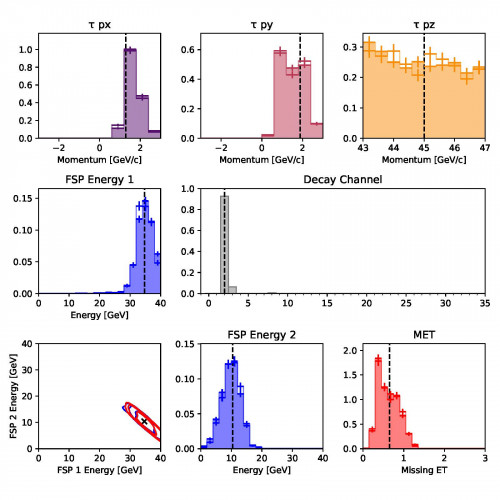
A comparison of some of the predictions from the Etalumis project’s inference compilation approach (outline histograms), which can achieve the same levels of precision as computationally intractable methods (filled histograms).
Deep Interpretability
For the LHC use case, the team trained a neural network to perform inference, learning to come up with good proposals about what detailed chain of physics processes from the simulator might have occurred. This required improvements to the PyTorch deep-learning framework to train a complex dynamic neural network on more than 1,000 nodes (32,000 CPU cores) of the Cori supercomputer at NERSC. As a result, training that would take months with the original unoptimized software on a single node can now be completed in less than 10 minutes on Cori. Scientists thus gained an opportunity to study the choices that went into producing each outcome, giving them a greater understanding of the data.
“In many cases you know there’s an uncertainty in determining the physics that occurred at an LHC collision but you don’t know the probabilities of all the processes that could have given rise to a particular observation; with Etalumis, you get a model of that,” Bhimji explains.
The deep interpretability that Etalumis brings to data analysis from the LHC could support major advances in the physics world. “Signs of new physics may well be hiding in the LHC data; revealing those signals may require a paradigm change from the classical algorithmic processing of the data to a more nuanced probabilistic approach,” says Kyle Cranmer, an NYU physicist who was part of the Etalumis project. “This approach takes us to the limit of what is knowable quantum mechanically.”
In addition to Wood, Baydin, Bhimji, and Cranmer, co-authors on the SC19 paper include Lei Shao, Lawrence Meadows, Mingfei Ma, Xiaohui Zhao, and Victor Lee from Intel; Lukas Heinrich from CERN; Bradley Gram-Hansen and Philip Torr from University of Oxford; Andreas Munk and Saeid Naderiparizi from University of British Columbia; Gilles Louppe from University of Liege; and Jialin Liu and Prabhat from NERSC.
NERSC is a U.S. Department of Energy Office of Science user facility.
About Computing Sciences at Berkeley Lab
High performance computing plays a critical role in scientific discovery. Researchers increasingly rely on advances in computer science, mathematics, computational science, data science, and large-scale computing and networking to increase our understanding of ourselves, our planet, and our universe. Berkeley Lab’s Computing Sciences Area researches, develops, and deploys new foundations, tools, and technologies to meet these needs and to advance research across a broad range of scientific disciplines.