
Pre-trained artificial intelligence (AI) foundation models have generated a lot of excitement recently, most notably with Large Language Models (LLMs) such as GPT4 and ChatGPT. The term “foundation model” refers to a class of AI models that undergo extensive training with vast and diverse datasets, setting the stage for their application across a wide array of tasks. Rather than being trained for a single purpose, these models are designed to understand complex relationships within their training data. These models can adapt to various new objectives through fine-tuning with smaller, task-specific datasets. Once fine-tuned, these models can accelerate progress and discovery by rapidly analyzing complex data, making predictions, and providing valuable insights to researchers. The magic lies in scaling the model, data, and computation in just the right way.
Scientists at Lawrence Berkeley National Laboratory (Berkeley Lab) and UC Berkeley recently studied whether the techniques used to develop these pre-trained models can be used to solve complex problems in scientific machine learning (SciML) – specifically by demonstrating how the AI models trained for one task can use that knowledge to improve on a different, but related task, a concept called “transfer learning.”
This pre-train and fine-tune paradigm is an increasingly important modus operandi (M.O.) in machine learning (ML), and it stands apart from conventional approaches, where a unique model is painstakingly built from scratch for each distinct problem and dataset. Instead, it defies traditional domain boundaries, weaving through diverse domain use cases and harnessing the potency of ML to extract wisdom from an array of disciplines and data sets.
Uncovering a promising M.O. for SciML
Is this “foundation model” approach even applicable in scientific machine learning (SciML)? The research team asked and affirmatively answered this question. By exploring pre-trained models based on partial differential equations (PDEs) – a mathematical framework that illuminates the dynamics of change in multiple variables such as time and space – the team’s research unveiled exciting opportunities to tackle complex scientific problems with increased efficiency and effectiveness. These PDE systems are a core component for many fundamental and applied problems, from climate modeling and molecular dynamics simulations to computational fluid dynamics and even the intricate tapestry of cancer growth modeling. Their paper will be published in the 2023 NeurlPS Proceedings in December 2023.
While the potential of ML models to estimate solutions to PDE problems has received a great deal of interest recently, the present landscape involves the arduous training of individual models for distinct PDE systems. In contrast, the team’s breakthrough findings reveal a novel method for applying ML in scientific domains. This approach involves using pre-trained SciML models and careful domain-specific fine-tuning, a promising M.O. of ML, to elegantly solve complex SciML challenges. Specifically, the research shows the models can glean insights from one task and seamlessly channel that knowledge to improve upon a different task through transfer learning. This revelation opens the potential to lay the cornerstone for an interdisciplinary SciML framework and pave the way for constructing SciML foundation models, potentially unlocking discoveries that would otherwise take longer to achieve.
“LLMs have received interest in many application areas, scientific domains included, as they should. But can the methodology used to develop them, which stands in stark contrast to the usual approach to model development, be used to develop analogously transformative models in other areas?” asked Michael Mahoney, Group Lead of the Machine Learning and Analytics (MLA) group in Berkeley Lab’s Scientific Data Division (SciData) and faculty member in the Department of Statistics at UC Berkeley. “Our study is the first to ask this question, and our results suggest that many aspects of the scientific modeling and computation process may need to be fundamentally rethought if the goal is to maximize the potential of machine learning methods to deliver on the promise of AI for science.”
Increased Efficiency and Effectiveness
The MLA group is also collaborating with multiple groups across Berkeley Lab and beyond – including at the National Energy Research Scientific Computing Center (NERSC), the Applied Mathematics and Computational Research Division (AMCR), and the U.S. Department of Energy (DOE) Scientific Discovery through Advanced Computing (SciDAC) program partners – on applying this general approach to specific scientific problems.
“This is an exciting development that has important implications for the SciDAC program, which is focused on tackling a wide range of large-scale scientific challenges across multiple disciplines,” said Leonid Oliker, Senior Scientist in AMCR’s Performance and Algorithms Research group and Deputy Director of the RAPIDS SciDAC Institute for Computer Science, Data, and AI. “This approach has tremendous potential to quickly target ML towards solving complex real-world challenges and accelerate scientific discovery across computational partnerships.”
By using large pre-trained models and then fine-tuning them with transfer learning, scientists can take on tasks that involve PDEs with reduced data requirements. The method reduces complexity, conserves computational resources, and slashes data demands, empowering scientists to conquer PDE challenges with efficiency and precision, especially for new applications that require expensive labeled data. The team examined various scenarios, investigating how different factors, such as the size of the pre-trained model, the scale of downstream data sizes, and the physics parameters, could influence the results. They also experimented with using a single pre-trained model, initially trained on a mix of physics problems, for a range of distinct applications.
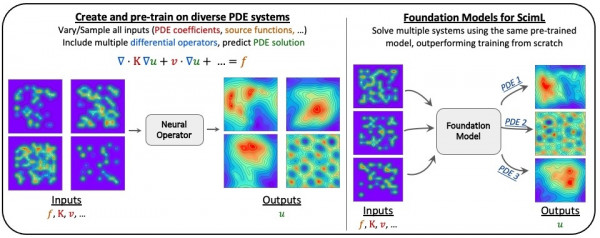
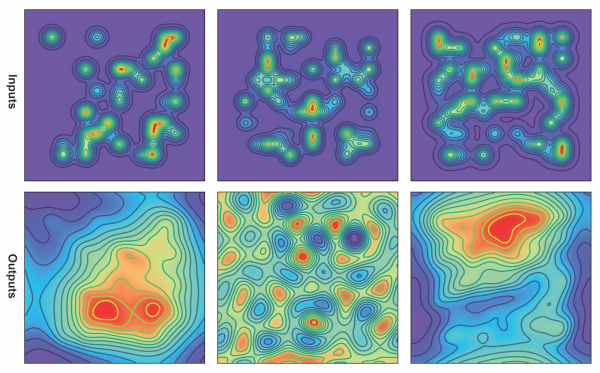
Figure 1: The setup involves creating diverse training datasets, simultaneously sampling PDE coefficients and source functions with various PDE operators, and input data distributions for pre-training. The pre-trained neural operator is then adapted with minimal fine-tuning for various downstream tasks, enabling it to transfer across different systems. Credit: Subramanian, Bhimji, Harrington, Morozov, Gholami, Keutzer, Mahoney.
Remarkable Adaptability
In a twist that defied the team’s expectations, the model displayed remarkable adaptability. Despite its original training encompassing a mix of different scientific problems, it managed to seamlessly pivot and excel in various downstream applications with different governing equations.
The insights gained from these findings highlight the potential of combining foundation model methods, the pre-train and fine-tune learning paradigm, to apply the new M.O. of ML in scientific domains. These approaches could pave the way for a substantial decrease in the number of training examples needed to achieve desired accuracy levels, even for tasks that are different from the initial pre-training phase. The process of fine-tuning these pre-trained models also amplifies performance improvements as the model size increases.
The pre-training workflows for this study were run on the Perlmutter system at NERSC. “We have achieved exciting preliminary results with the potential to bridge supercomputing with the future of AI and science,” said Shashank Subramanian, lead author and Machine Learning Engineer at NERSC. He emphasized that building these foundation models can require substantial compute power from HPC resources like NERSC. “Once trained, these models hold enormous promise for accelerating complex simulations and enhancing our scientific understanding,” he said. Building on the exciting results achieved through the pre-training workflows, the team explored how foundation models play a valuable role in SciML tasks.
The Foundation of SciML
“Foundation models have great potential for SciML tasks, serving as an additional tool in our toolkit, working alongside the tried-and-true methods we already have in SciML. Together, they help us come up with new solutions from data,” said Amir Gholaminejad, a Research Scientist at Berkeley AI Research (BAIR) and Sky Lab at UC Berkeley. “For many SciML problems, solving the underlying equations with numerical methods can be very computationally expensive. Foundation models can be considered problem-solving partners that provide a good initial solution – a head start – to solving complex problems. Then we can refine that initial solution with classical methods.” Gholaminejad emphasizes that there is still a significant amount of uncharted territory when it comes to the generalization capability of these models, something that warrants further investigation.
With this goal in mind, the team made its code publicly available to foster collaboration and transparency within the scientific community. By sharing their work, the researchers are inviting others to build upon their findings, validate the outcomes, and potentially develop new techniques and applications. This approach fosters the exchange of knowledge, facilitating the collective advance of the field of SciML.
This research was supported by the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research, Scientific Discovery through the Advanced Computing (SciDAC) program at Berkeley Lab and used the Perlmutter system at NERSC.
About Computing Sciences at Berkeley Lab
High performance computing plays a critical role in scientific discovery. Researchers increasingly rely on advances in computer science, mathematics, computational science, data science, and large-scale computing and networking to increase our understanding of ourselves, our planet, and our universe. Berkeley Lab's Computing Sciences Area researches, develops, and deploys new foundations, tools, and technologies to meet these needs and to advance research across a broad range of scientific disciplines.