




 Instagram
Instagram YouTube
YouTubeScience Applications
Machine learning (ML) and artificial intelligence (AI) are impacting many science domains in analyzing data, solving inverse problems, approximating time-consuming simulations or experiments, controlling complex systems, and in design and engineering. Berkeley Lab is well placed to interface novel AI/ML techniques with different science areas due to the variety of science ongoing at the lab and making use of lab-based facilities such as the National Energy Research Scientific Computing Center (NERSC).
Berkeley Lab researchers are actively involved in in-depth engagements with domain science partners to build AI and learning algorithms directly into modeling and simulation applications, experimental and observational data pipelines, and the operation of facilities and infrastructure. The active community means that lessons learned are transferred across domains with cross-cutting efforts using particular techniques such as generative models or graph neural networks or tackling common challenges such as data management or interactivity. Various projects exist to enable such collaborations, including Berkeley Lab’s LDRD initiatives, the Exascale Computing Project’s (ECP’s) ExaLearn project, and NERSC’s learning applications in the NESAP partnership program.
For experimental data, machine learning can be incorporated into all stages including all stages, including filtering, compression, and reduction in situ at the instrument; smart scheduling of facilities; advanced analytics; and statistics/machine learning on HPC machines. For modeling and simulation applications, we build on our existing strength and ownership of these applications to use learning where data-driven models are needed, to analyze outputs, or to manage ensemble calculations. We also develop methods for facilities and infrastructure management, optimizing resource allocation, and detecting problems such as component failures and cyber incidents.
Projects
New Battery Designs and Quality Control with Deep Learning
In an ever-demanding world for zero-emission clean energy sources, vehicle electrification will bring major contributions as each clean car that substitutes one based on fossil fuel could save 1.5 tons of carbon dioxide per year. To expand the e-vehicle fleet, new solutions to store energy must deliver lighter, longer ranges, and more powerful energy batteries, such as solid-state lithium metal batteries (LMB). Different from traditional lithium-ion, LMB uses solid electrodes and electrolytes, providing superior electrochemical performance and high energy density. One of the challenges of this new technology is to predict cycling stability and prevent the formation of lithium dendrite growth. These morphologies are key to the LMB quality, and they can be captured and analyzed using X-ray microtomography. This project focuses on new deep learning based on U-net, Y-net, and viTransformers for detection and segmentation of defects in LMB. Contact: Dani Ushizima
Self-Supervised Learning for Cosmological Surveys
Sky surveys are the largest data generators in astronomy, making automated tools for extracting meaningful scientific information an absolute necessity. The rich, unlabeled image data from such surveys can be used to develop powerful self-supervised AI models that distill low-dimensional representations which are robust to symmetries, uncertainties, and noise in each image; these semantically meaningful representations make the self-supervised model immediately useful for downstream tasks like morphology classification, redshift estimation, similarity search, and detection of rare events, paving new pathways for scientific discovery. Contact: Peter Harrington
Feedstock to Function
The goal of this project is to improve bio-based product and fuel development through adaptive techno-economic and performance modeling. Toward this end, we are developing a comprehensive Feedstock to Function software tool (F2FT) that harnesses the power of machine learning to predict the properties of high-potential molecules (fuels, fuel co-products, and other bioproducts) derived from biomass. This tool can also be used to evaluate the cost, benefits, and risk of promising biobased molecules or biofuels to enable faster, less expensive bioprocess optimization and scale-up. Contact: Vi Rapp (Rapp on the Web)
Towards Fast and Accurate Predictions of Radio Frequency Power Deposition and Current Profile via Data-Driven Modeling
Three machine learning techniques (multilayer perceptron, random forest, and Gaussian process) provide fast surrogate models for lower hybrid current drive (LHCD) simulations. A single GENRAY/CQL3D simulation without radial diffusion of fast electrons requires several minutes of wall-clock time to complete, which is acceptable for many purposes, but too slow for integrated modeling and real-time control applications. The machine learning models use a database of more than 16,000 GENRAY/CQL3D simulations for training, validation, and testing. Latin hypercube sampling methods ensure that the database covers the range of nine input parameters with sufficient density in all regions of parameter space. The surrogate models reduce the inference time from minutes to milliseconds with high accuracy across the input parameter space. Contacts: Talita Perciano, Zhe Bai
Inferring Properties of Nanoporous with Machine Learning and Topology
We use persistent homology to describe the geometry of nanoporous materials at various scales. We combine our topological descriptor with traditional structural features and investigate the relative importance of each to the prediction tasks. Our results not only show a considerable improvement compared to the baseline, but they also highlight that topological features capture information complementary to the structural features. Furthermore, by investigating the importance of individual topological features in the model, we are able to pinpoint the location of the relevant pores, contributing to our atom-level understanding of structure-property relationships. Contact: Dmitriy Morozov
Evaluating State Space Discovery by Persistent Cohomology in the Spatial Representation System
Persistent cohomology is a powerful technique for discovering topological structure in data. Strategies for its use in neuroscience are still undergoing development. We comprehensively and rigorously assess its performance in simulated neural recordings of the brain's spatial representation system. Our results reveal how dataset parameters affect the success of topological discovery and suggest principles for applying persistent cohomology to experimental neural recordings. Contact: Dmitriy Morozov
Rotational Dynamics and Transition Mechanisms of Surface-Adsorbed Proteins
Living systems create a wide range of biomolecular arrays with complex functions and exquisite organization. This has inspired synthetic equivalents for a range of applications, enabling new high-throughput approaches to biocomposites, diagnostics, and materials research. This study with data analyses helps broaden the physical understanding of biomolecular assembly by tracking motion at unprecedented resolution and defining a general procedure for using in situ visualization and machine learning to explore such dynamics. This research characterizes the “energy landscape” for protein orientation and, by analyzing the motion of the proteins, shows how that energy landscape controls the rate of motion between different orientations. Contact: Oliver Ruebel
Mobiliti
Mobiliti is a traffic simulator for large-scale transportation networks, enabling users to model dynamic congestion and vehicle rerouting behavior in response to hypothetical traffic and network events. We are currently exploring the use of deep reinforcement learning along with graphical models (RL and DCRNNs) to predict traffic, optimize traffic signal controllers, and quantify their impact on system-level congestion. Contact: Cy Chan
Exa.TrkX: HEP Pattern Recognition at the Exascale
Reconstructing the trajectories of thousands of charged particles from a collision event as they fly through a HEP detector is a combinatorially hard pattern recognition problem. Exa.TrkX, a DOE CompHEP project and a collaboration of data scientists and computational physicists from the ATLAS, CMS, and DUNE experiments, is developing Graph Neural Network models aimed at reconstructing millions of particle trajectories per second from Petabytes of raw data produced by the next generation of detectors at the Energy and Intensity Frontiers. Exa.TrkX is also exploring the scaling of distributed training of GNN models on DOE pre-exascale systems and deploying GNN models with microsecond latencies on FPGA-based real-time processing systems. Contact: Paolo Calafiura
4DCamera Distillery (National Center for Electron Microscopy)
4DCamera Distillery is a program that will develop and deploy methods and tools based on AI and ML to analyze electron scattering information from the data streams of fast direct electron detectors. The team behind the effort, composed of researchers from Brookhaven National Laboratory, Oak Ridge National Laboratory, Argonne National Laboratory, Sandia National Laboratory, and Los Alamos National Laboratory, as well as Berkeley Lab, will address both the critical need for data reduction tools for these detectors and capitalize on the scientific opportunities to create new modes of measurement and experimentation that are enabled by fast electron detection. Contacts: Andrew Minor, Colin Ophus
Simulation and Control in Large Scale Power Systems
As more wind, solar, and storage systems come online, power systems are becoming increasingly difficult to simulate and thus to predict and control their performance. This project aims to develop new tools at the intersection of scientific machine learning and power systems engineering that will accelerate the simulation of these more complex power systems in near real-time. Contact: Duncan Callaway (Callaway on the Web)
DeepAir
Deep Learning and Satellite Imagery to Estimate Air Quality Impact at Scale, or DeepAir, uses deep learning algorithms to analyze satellite images combined with traffic information from cell phones and data already being collected by environmental sensors to improve air quality predictions. The resulting analysis aims to ultimately inform the design of more efficient and more timely interventions, such as the San Francisco Bay Area's “Spare the Air” days. Contact: Marta C. González (González on the Web)
AR1K: Engineering Agriculture through Machine Learning in BioEPIC
In an effort to revolutionize agriculture and create sustainable farming practices that benefit both the environment and farms, researchers from Berkeley Lab, the University of Arkansas, and Glennoe Farms are bringing together molecular biology, biogeochemistry, environmental sensing technologies, and machine learning and applying them to soil research. This project aims to reduce the need for chemical fertilizers and enhance soil carbon uptake to improve the long-term viability of land and increase crop yields. Contacts: Ben Brown (Brown on the Web), Haruko Wainwright (Wainwright on the Web)
Flash Drought Prediction
Flash droughts come on seemingly without warning, and sometimes with devastating effects. In this NSF PREEVENTS project, we are working to advance the understanding and subseasonal-to-seasonal prediction of flash droughts and their associated heat extremes. We are developing machine-learning-based estimates of photosynthesis, evapotranspiration, and respiration at high resolution, in combination with remotely sensed estimates of evaporative stress, to define and characterize flash drought. Contact: Trevor Keenan (Keenan on the Web)
Data Analytics for Commercial Buildings
State-of-the-art analytics software and modeling tools can provide valuable insights into efficiency opportunities. However, prior research has shown that key barriers include relatively limited data sources (smart meters and weather being most common in commercial tools), or reliance upon user-provided inputs for which default values may be the fallback. There is great opportunity to apply techniques based on multi-stream data fusion and machine learning to overcome these challenges. Contact: Jessica Granderson (Granderson on the Web)
The Chemical Universe through the Eyes of Generative Adversarial Neural Networks
This project is developing generative machine learning models that can discover new scientific knowledge about molecular interactions and structure-function relationships in chemical sciences. The aim is to create a deep learning network that can predict properties from structural information but can also tackle the “inverse problem,” that is, deducing structural information from properties. To demonstrate the power of the neural network, we focus on bond breaking in mass-spectrometry, combining experimental data with HPC computational chemistry data. Funded by a Lab Directed Research and Development (LDRD) grant. Contact: Bert de Jong (de Jong on the Web)
Transformers for Topic Modeling and Recommendation
This project focuses on mining scientific articles repositories such OSTI, Springer, and other databases by creating Bidirectional Encoder Representations from Transformers (BERT). This new technique can turn text data into information that helps to identify key topics within certain science domains. For example, the main technologies for quality control of batteries, key designs for avoiding short-circuiting, and new polymeric elements that improve insulation of electrodes. Besides topic modeling, our schemes use BERT to provide an unsupervised scheme to organize scientific articles and enable recommendations that are aware of text semantics. Contacts: Dani Ushizima, Eric Chagnon
Codesign of Ultra-Low-Voltage, Beyond CMOS Microelectronics
The goal of the project is developing the co-design framework of atoms-to-architectures to enable sub-100mV switching of non-volatile logic-in-memory, and ultra-efficient digital signal processing for applications such as IoT, sensors and detectors. The co-design of next-generation hardware is currently a static process that involves human-in-the-loop evolution via repeated experiments, modeling, and design space exploration. Using AI, our goal is to accelerate the pace at which we can iterate on co-designing beyond CMOS microelectronics. Specifically, in the reporting period, we focused on two specific activities. Contact: Lavanya Ramakrishnan
News
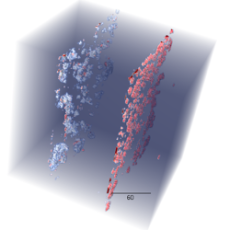
Advancing New Battery Design with Deep Learning
A team of researchers from Berkeley Lab and UC Irvine has developed deep-learning algorithms designed to automate the quality control and assessment of new battery designs for electric cars. Read More »
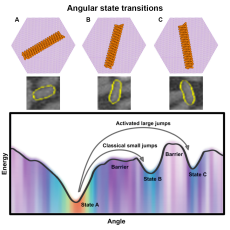
Computational Analysis Enables Breakthrough in Biomolecular Dynamics
A new study with data analyses from Berkeley Lab computational researchers helps broaden the physical understanding of biomolecular assembly by tracking motion at high resolution and defining a general procedure for using in situ visualization and machine learning to explore such dynamics. This research characterizes the “energy landscape” for protein orientation and shows how that energy landscape controls the rate of motion between different orientations. Read More »
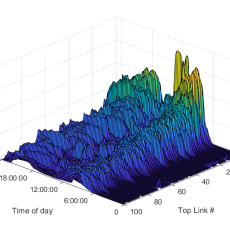
Mobiliti: A Game Changer for Analyzing Traffic Congestion
Berkeley Lab researchers have developed a software tool that uses supercomputing resources at the National Energy Research Scientific Computing Center to accurately simulate traffic flow throughout the San Francisco Bay Area road networks and provide estimates of the associated congestion, energy usage, and productivity loss. Read More »

'Farm of the Future' Project Marries Microbiology, Machine Learning
There’s a farm in Arkansas growing soybeans, corn, and rice that is aiming to be the most scientifically advanced farm in the world. Soil samples are run through powerful machines to have their microbes genetically sequenced, drones are flying overhead taking hyperspectral images of the crops, and soon supercomputers will be crunching the massive volumes of data collected. Read More »